The PHIL System
PHIL is a software tool, written in Haskell, for filtering information from XML data. Essentially, the system implements a simple declarative language which allows one to extract relevant data as well as to exclude useless and misleading contents from an XML document by matching patterns against XML documents.
The matching mechanism (inspired by [2]) employes a cost-based pattern transformation algorithm which searches for patterns in an approximate way (i.e. modulo renaming, insertion, and deletion of XML items) and ranks the results w.r.t. their cost. In order to improve efficiency, the implementation uses sophisticated indexing techniques and exploits laziness to automatically avoid the construction of unnecessary data structures.
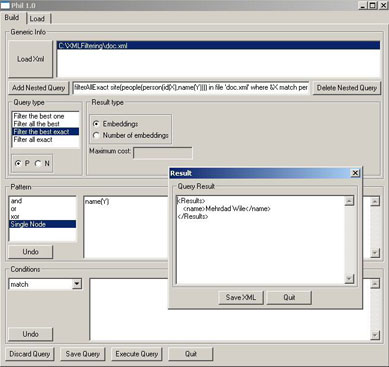
A technical report describing the system is available [here].