A connected component of an undirected graph is a maximal set of nodes such that each pair of nodes is connected by a path. Connected components form a partition of the set of graph vertices, meaning that connected components are non-empty, they are pairwise disjoints, and the union of connected components forms the set of all vertices. Equivalently, we can say that the relation that associates two nodes if and only if they belong to the same connected component is an equivalence relation, that is it is reflexive, symmetric, and transitive.
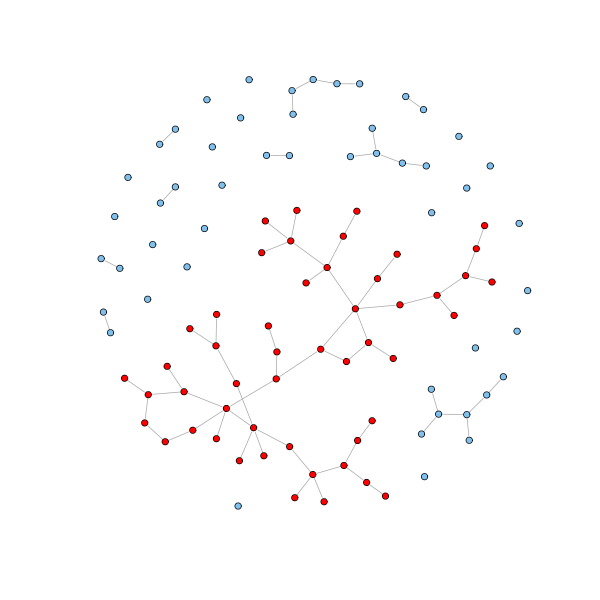
In real undirected networks, we typically find that there is a large component (the giant component) that fills most of the network - usually more than half and not infrequently over 90% - while the rest of the network is divided into a large number of small components disconnected from the rest. Both the random model and the preferential attachment model generate networks with giant components. In particular, random graphs with $n$ nodes and edge probability $p$ show a giant component as soon as $p > 1/n$. If follows that if the mean node degree $p (n-1) \geq 1$, then $p \geq 1/(n-1) > 1/n$, and we have the giant component.
The situation is exemplified in the following graph, which is drawn according to the random model:
There are some networks for which the largest component fills the entire network. In these cases there is always a good reason. The Internet is a good example. There would be no point in being part of the Internet if you are not part of its largest component, since that would mean that you are disconnected from and unable to communicate with almost everyone else. Other examples include power grids, train routes, and electronic circuits.
Can a network have two or more large components that fill a sizable fraction of the entire graph? Usually the answer is no. The argument is that if a network of $n$ nodes was divided into two large components of about $n/2$ nodes each, then there would be $n^2/4$ possible pairs of nodes such that one node was in one large component and the other node in the other large component. If there is an edge between any of these pairs, than the components are joined together into a single component. It is highly unlikely that not one such pair would be connected.
And what about networks with no large component? It is certainly possible. One example would be the network of immediate family ties. Networks like those, however, are not studied with the network analysis toolkit, since there is little to be gained by applying these techniques to such networks.
A useful generalization of the concept of connected component is the k-connected component (or simply k-component). A $k$-component is a maximal set of vertices such that each is reachable from each of the others by at least $k$ node-independent paths (paths that do not share any node unless the source and the target ones). For the common cases $k=2$ and $k=3$, $k$-components are called bicomponents and tricomponents.
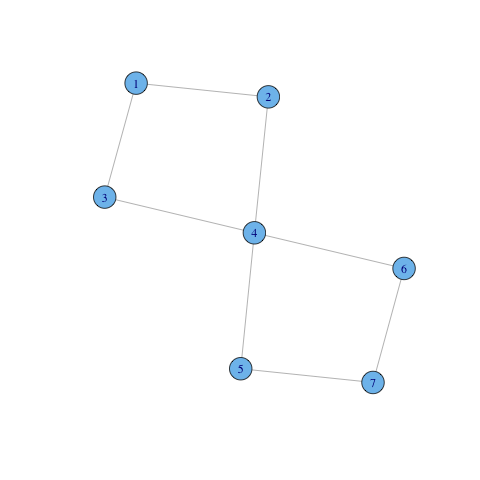
A 1-component is just an ordinary component. Moreover, for $k \geq 2$, a $k$-component is nested within a $k-1$ component (every pair of nodes connected by $k$ independent paths is also connected by $k-1$ independent paths). Notice that for $k \geq 2$, $k$-components may overlap. Hence $k$-components do not define a partition of (or equivalence relation on) the set of vertices. An example is provided in the next graph. There are two bicomponents overlapping: $C_1 = \{1,2,3,4\}$ and $C_2 = \{4,5,6,7\}$. Vertex $4$ belongs to both components.
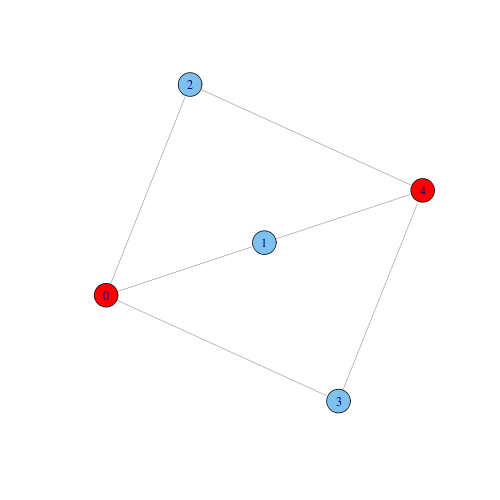
Note also that for $k \geq 3$, the $k$-components in a network can be non-contiguous. For instance, in the next graph, nodes 0 and 4 form a non-contiguous tricomponent. Notice that the tricomponent is embedded into a (contiguous) bicomponent that covers the whole graph.
The number of node-independent paths between two nodes is also known as the connectivity of the two nodes. It can be thought as a measure of how strongly connected the two nodes are. On the other hand, the smallest set of vertices that would have to be removed in order to disconnect two nodes not linked by an edge is called the minimum cut set for the two vertices. It holds that the size of the minimum cut set for two nodes (not linked by an edge) is exactly the connectivity of the two nodes. It follows that a $k$-component remains connected as soon as less than $k$ nodes (and the incident edges) are removed. For instance, a bicomponent is still connected if we remove any of its nodes, a tricomponent is still connected if we remove any two of its nodes. The minimum connectivity of any pair of nodes in a graph is the connectivity (or cohesion) of the graph.
For these reasons, the idea of $k$-component is associated with the idea of network robustness. In data networks such as Internet the connectivity of two routers is the number of independent routes that data might take between the two routers, and it is also the minimum number of routers that would have to fail to cut the data connection between the two endpoints. One would hope that most of the network backbone is a $k$-component with high $k$, so that it would be difficult for points on the backbone to lose connection with one another.
As for normal connected components, usually there is one large biconnected component, and many much smaller biconnected components. For example, we have analyzed the collaboration network for computer science. Two computer scientists are linked if they published at least one paper together, as recorded in DBLP, the most complete bibliography for computer science. The network contains 688,642 nodes and 2,283,764 edges. The computer science collaboration network is widely connected. The largest connected component counts 583,264 scholars, that is 85% of the entire network. There are two second largest components, the size of which, only 40 nodes, is negligible compared to that of the giant component. The largest biconnected component counts 418,001 nodes, or 61% of the entire network, and it covers a share of 72% of the largest connected component. The second-largest biconnected component has only 32 nodes.
The component structure of directed networks is more complicated than for undirected ones. Directed graphs have weakly and strongly connected components. Two vertices are in the same weakly connected component if they are connected by a path, where paths are allowed to go either way along any edge. The weakly connected components correspond closely to the concept of connected component in undirected graphs and the typical situation is similar: there is usually one large weakly connected component plus other small ones.
Two vertices are in the same strongly connected component if each can reach and is reachable from the other along a directed path. Strongly connected components form a partition of the vertex set and define an equivalence relation among nodes. Not all directed networks have a large strongly connected component. In particular, any acyclic network has no strongly connected components of size greater than one. Real-life networks that are (almost) acyclic are article citation networks and food webs.
Here is an example of a directed network with the largest strongly connected component highlighted in red:

Associated with each strongly connected component is an out-component (the set of vertices that can be reached from the strongly connected component but that cannot reach it) and an in-component (the set of vertices that can reach the strongly connected component but that are note reachable from it). Note that in and out components are disjoint: if a node would belong to both the in and out component of a strongly connected component, then that node would be part of the strongly connected component. Moreover, notice that there are no edges from nodes in the out-component to nodes in the in-components, otherwise the involved nodes would be part of the strongly connected component.
Related to network connectivity and robustness is percolation, one of the simplest of processes taking place on networks. Imagine taking a network and removing some fraction of its vertices, along with the edges connected to those vertices. This process is called percolation, and can be used as a model of a variety of real-world phenomena. The failure of routers on the Internet, for instance, can be formally represented by removing the corresponding vertices and their attached edges from a network representation of the Internet. In fact, about 3% of the routers on the Internet are non-functional for one reason or another at any one time, and it is a question of some practical interest what effect this will have on the performance of the network.
Another example of a percolation phenomenon is the vaccination or immunization of individuals against the spread of disease. Diseases spread through populations over the networks of contacts between individuals. But if an individual is vaccinated against a disease and therefore cannot catch it, then that individual does not contribute to the spread of the disease. Of course, the individual is still present in the network, but, from the point of view of the spread of the disease, might as well be absent, and hence the vaccination process can again be formally represented by removing vertices.
One can see immediately that percolation processes can give rise to some interesting behaviors. The vaccination of an individual in a population, for example, not only prevents that individual from becoming infected but also prevents them from infecting others, and so has a knock-on effect in which the benefit of vaccinating one individual is felt by more than one. As we will show, this knock-on effect means that in some cases the vaccination of a relatively small fraction of the population can effectively prevent the spread of disease to anyone, an outcome known as herd immunity.
Similar effects crop up in our Internet example, although in that case they are usually undesirable. The removal or failure of a single router on the Internet prevents that router from receiving data, but also prevents data from reaching others via the failed one, forcing traffic to take another route - possibly longer or more congested - or even cutting off some portions of the network altogether. One of the goals of percolation theory on networks is to understand how the knock-on effects of vertex removal or failure affect the network as a whole.
There is more than one way in which vertices can be removed from a network. In the simplest case they could be removed purely at random: we could for example take away some specified fraction of the vertices chosen uniformly at random from the entire network. One popular alternative removal scheme is to remove vertices according to their degree in some fashion. For instance, we could remove vertices in order of degree from highest to lowest, an approach that turns out to make an effective vaccination strategy for the control of disease. Any other node centrality measures can be used as an alternative.