Stefano Mizzaro
Department of Mathematics and Computer Science - University of Udine
Via delle Scienze, 206 - Loc. Rizzi
33100 - Udine - Italy
E-mail: mizzaro@dimi.uniud.it
WWW: http://www.dimi.uniud.it/~mizzaro
(postscript-gzipped version here)
* Document, the physical entity that the user of an IR system will obtain after his seeking of information;
* Surrogate, a representation of a document, consisting of one or more of the following: title, list of keywords, author(s) name(s), bibliographic data, abstract, and so on;
* Information, the (not physical) entity that the user receives/creates when reading a document.
* Problem, that a human being is facing and that requires information for being solved;
* Information need, a representation of the problem (implicit) in the mind of the user. It is different from the problem because the user might not perceive in the correct way his problem [2,3];
* Request, a representation of the information need of the user in a 'human' language, usually in natural language;
* Query, a representation of the information need in a 'system' language, e.g. boolean.
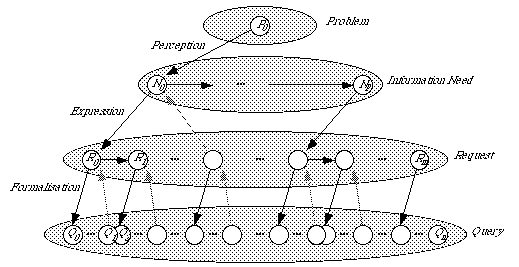
These entities appear if one analyses the interaction between a user and an IR system (see Fig. 1): the user has a problem, perceives it and builds the information need, expresses the information need in a request, and formalises (perhaps with the help of an intermediary) the request in a query. Perception, expression, and formalisation are not so simple as it might seem at first glance, since some well-known problems (ASK, label effect, vocabulary problem, and so on, see [4]) appear.
Fig. 1: Problem, information need, request, and query.
* Topic, that refers to the subject area to which the user is interested. For example, 'the concept of relevance in information science';
* Task, that refers to the activity that the user will execute with the retrieved documents. For example, 'to write a survey paper on ...';
* Context, that includes everything not pertaining to topic and task, but however affecting the way the search takes place and the evaluation of results. For example, documents already known by the user (and thus not worth being retrieved), time and/or money available for the search, and so on.
Therefore, a surrogate (a document, some information) is relevant to a
query (request, information need, problem) with respect to one or more of these
components.
Fig. 2: The dynamic interaction user-IR system.
1. Surrogate, document, information;
2. Query, request, information need, problem;
3. Topic, task, context, and each combination of them;
4. The various time instants from the arising of the user's problem until its solution.
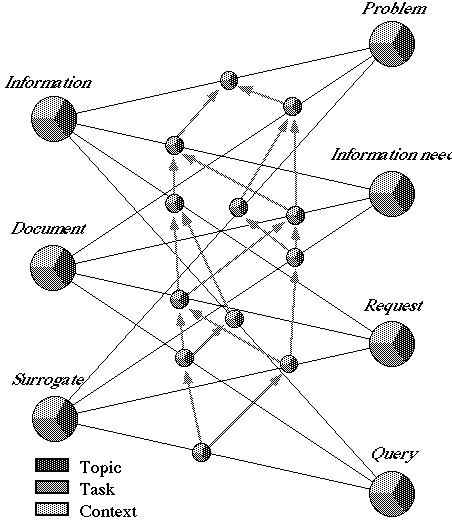
The situation described so far is (partially) represented in Fig. 3: on the
left hand side, there are the elements of the first dimension, and on the right
hand side there are the elements of the second one. Each line linking two of
these objects is a relevance (graphically emphasised by a circle on the line).
It is more difficult to graphically represent the third dimension, since its
elements are only partially (and not totally) ordered. In figure, the three
grey levels represent the three components (induced in each of the relevances
by the elements of the first two dimensions), emphasising that a relevance may
concern one or more of them. For simplifying the figure, the time dimension is
not represented. Finally, the grey arrows represent a partial order among the
relevances. This order denotes how much a relevance is near to the relevance of
the information received to the problem for all three components, the one to
which the user is interested, and how difficult is to measure it. The number of
steps (arrows) needed to reach the topmost small circle is an indication of the
distance of each kind of relevance from the relevance of the information
received to the problem.
Fig. 3: The various kinds of relevance.
1. The kind of relevance judged (see the previous section);
2. The kind of judge (for instance, it is possible to distinguish between user and non-user);
3. What the judge can use (surrogate, document, or information) for expressing his relevance judgement. It is the same dimension used for relevance, but it is needed since, for instance, the judge can assess the relevance of a document on the basis of a surrogate;
4. What the judge can use (query, request, information need, or problem) for expressing his relevance judgement (needed for the same reason of the previous point 3);
5. The time at which the judgement is expressed (at a certain time point, one may obviously judge the relevance in another time point).
* can easily be formalised using set theory, see [8,9];
* shows how it is short-sighted to speak merely of 'system relevance' (the relevance as seen by an IR system) as opposed to 'user relevance' (the relevance in which the user is interested), and how 'topicality' (a relevance for what concerns the topic component) is conceptually different from 'system relevance';
* is useful for avoiding ambiguities on which relevance (judgement) we are talking about;
* has to be considered in the implementation of IR systems working closer to the user; and
* emphasises that it is not so strange if different studies on relevance obtain different results, as one must pay attention to both which kind of relevance is measured and which kind of relevance judgement is adopted.
[1] S. Mizzaro, to appear. "Relevance: The Whole History". Accepted for the publication in Journal of the American Society for Information Science.
[2] S. Mizzaro, 1996. "A cognitive analysis of information retrieval." Accepted for the publication in Proceedings of the CoLIS2 conference, Copenhagen, October 13-16 1996.
[3] S. Mizzaro, 1996. "On the foundations of information retrieval." Accepted for the publication in Proceedings of the Annual Conference AICA96, Rome, September 24-27 1996.
[4] P. Ingwersen, 1992. Information Retrieval Interaction, Taylor Graham, London.
[5] G. Brajnik, S. Mizzaro, and C. Tasso, 1996. "Evaluating User Interfaces to Information Retrieval Systems: A Case Study on User Support". In Proceedings of the SIGIR96, Zurich, August 1996, pp. 128-136 .
[6] G. Brajnik, S. Mizzaro, and C. Tasso, 1996. "La valutazione di interfacce intelligenti per il reperimento di informazioni". In AI*IA Notizie (supplement to Nr. 3, Year IX, September 1996), pp. 36-37. (In Italian).
[7] G. Brajnik, S. Mizzaro, and C. Tasso, 1995. "Interfacce intelligenti a banche di dati bibliografici". In Sistemi evoluti per basi di dati, D. Saccà (editor), pp. 95-128, Franco Angeli, Milano. (In Italian).
[8] S. Mizzaro, 1995. "Le differenti relevance in information retrieval: una classificazione." In Proceedings of the Annual Conference AICA95, pages 361-368. (In Italian).
[9] S. Mizzaro, 1996. "Relevance: the whole (hi)story". Technical Report UDMI/12/96/RR, Dipartimento di Matematica e Informatica, University of Udine.
{kind=link}
{kind=link}
{kind=link}