MySQL
MySQL è un DBMS relazionale creato da Michael "Monty" Widenius nel 1995 e attualmente posseduto e sviluppato dall'azienda svedese MySQL AB (AB sta per aktiebolag, cioè società per azioni).
MySQL viene distribuito con una doppia licenza: una licenza commerciale (a pagamento), che consente di includere le funzionalità di MySQL nello sviluppo di un proprio software e vendere tale software con licenza commerciale. Una licenza libera (GNU General Public License, GPL), che consente si scaricare liberamente i sorgenti e gli eseguibili, modificare i sorgenti e ridistribuirli a patto che il prodotto creato sia distribuito con la licenza GPL. In ogni caso, MySQL AB mantiene i diritti sui sorgenti e sul marchio MySQL, che quindi non può essere usato come nome nel software distribuito.
MySQL funziona su diverse piattaforme, in particolare, Linux, Mac OS X e MS Windows. E' possibile scaricare il DBMS dal sito di MySQL AB. Il sito di MySQL AB contiene una estesa documentazione sul DBMS, in particolare spiega come installarlo.
Il pacchetto MySQL contiene diversi programmi. I principali sono i seguenti:
- mysqld. Questo è il server MySQL che accoglie le richieste (interrogazioni) dei client. Lo script mysqld_safe è il modo più comune di lanciare il server, in quanto lo fa ripartire qualora esso termini in modo anomalo;
- mysql. Questo è il client MySQL che permette connettersi al server e eseguire le interrogazioni SQL;
- mysqladmin. Serve per amministrare il server MySQL, ad esempio per terminarlo;
- mysqlshow. Serve per ottenere informazioni sulla base di dati, sulle tabelle e sulle colonne;
- mysqldump. Serve per esportare schemi e tabelle su file di testo. Il client mysql oppure il programma mysqlimport sono in grado di caricare tabelle leggendole dai file esportati;
- mysqlhotcopy. Serve per esportare una base di dati o singole tabelle nel formato interno usato da MySQL. Per recuperare la base di dati basta copiare i file esportati nella cartella dei dati di MySQL.
Tutti i comandi che seguono sono stati testati su MySQL versione 5.0.37. Di seguito, assumeremo che la cartella bin della directory di installazione di MySQL sia nella variabile d'ambiente PATH del sistema operativo. Per eseguire dei comandi SQL occorre che il server sia acceso. Per avviare il server, spostarsi nella cartella di installazione di MySQL e usare il comando:
mysqld_safe
Per spegnere il server, usare il comando:
mysqladmin -u user -p shutdown
dove user è un utente con il privilegio di shutdown (verrà richiesta la parola chiave per l'utente).
Se il server è acceso, è possibile connettere un client al server con il comando:
mysql -h host -u user -pdove host è la macchina su cui gira il server di MySQL e user è l'utente che vuole connettersi. La parola chiave può essere specificata dopo l'opzione -p (senza spazi di separazione) oppure, più saggiamente, è possibile evitare di scriverla in chiaro. In tal caso viene richiesto l'inserimento della parola chiave in modo criptato. Se il server gira sulla macchina su cui si sta lavorando (identificata con localhost), l'opzione -h host può essere omessa. Esiste un utente root, la cui parola chiave è inizialmente nulla, e un utente anonimo, con nome utente e parola chiave entrambi nulli. Ne deriva che la prima volta è possibile avviare il client con i comandi mysql -u root (accedendo come root) oppure mysql (accedendo come utente anonimo).
Una volta avviato, il client è pronto a ricevere dall'utente i comandi da rivolgere al server. I comandi possono essere inseriti in tre modi:
- scrivendo il comando direttamente dal monitor di MySQL, cioè dalla linea di comando che si ottiene dopo aver avviato il client. Un comando SQL può essere spezzato su più righe e termina sempre con il simbolo ; oppure \g oppure \G (quest'ultimo mostra il risultato verticalmente). Un comando può essere annullato con \c;
- scrivendo il comando in un file e, dal monitor di MySQL, eseguendo il file con il comando source. Ad esempio:
source data/univ/sql/insert.sql;
- dalla linea di comando della shell del sistema operativo, in questo modo:
mysql -e "query" database
dove query è l'interrogazione SQL e database è il nome della base di dati da interrogare. E' anche possibile specificare host, user e password, se necessari. - dalla linea di comando della shell del sistema operativo, in quest'altro modo:
mysql database < queryFile
dove queryFile è il nome di un file che contiene l'interrogazione SQL e database è il nome della base di dati da interrogare. E' anche possibile specificare host, user e password, se necessari.
Di seguito, simuliamo la creazione, il popolamento e l'interrogazione di una semplice base di dati denominata univ che registra gli esami superati dagli studenti di una facoltà universitaria:
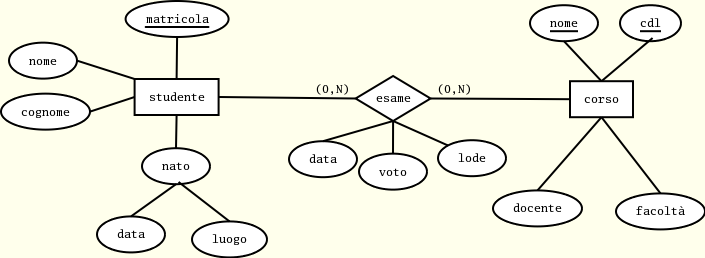
studente(matricola, nome, cognome, data, luogo)
corso(nome, cdl, facolta, docente)
esame(studente, corso, cdl, data, voto, lode)
esame(studente) --> studente(matricola)
esame(corso, cdl) --> corso(nome, cdl)
Useremo comandi SQL di MySQL appartenenti alle seguenti categorie ordinate logicamente:
- Amministrazione degli utenti
- Questi comandi permettono di creare e rimuovere utenti, assegnare loro privilegi e parola chiave.
- Definizione dello schema
- Questi comandi permettono di creare, modificare, e rimuovere le varie componenti dello schema della base di dati.
- Informazioni sullo schema
- Questi comandi permettono di stampare informazioni sullo schema della base di dati.
- Aggiornamento e interrogazione
- Questi comandi permettono di aggiornare il contenuto della base di dati e di interrogarla.
- Salvataggio e ripristino
- Questi comandi permettono di salvare una base di dati e di ripristinarla a partire dai file salvati.
Il primo passo da fare è creare un nuovo utente e assegnargli i privilegi. Per entrambe le cose esiste il comando grant. Ad esempio, per creare un utente alan con parola chiave nala e assegnargli tutti i privilegi su tutti i database, inclusa la possibilità di usare il comando grant, su può usare il seguente comando:
grant all privileges on *.* to 'alan'@'localhost' identified by 'nala' with grant option;
E' possibile essere più selettivi dando solo alcuni privilegi su alcune tabelle (o colonne) di alcune basi di dati. Ad esempio, il seguente crea (se già non esiste) l'utente alan e gli assegna il solo privilegio di effettuare select sulla tabella esame del database univ:
grant select on univ.esame to 'alan'@'localhost' identified by 'nala'
E' possibile usare il privilegio usage per creare un utente senza privilegi. Le informazioni su utenti e i loro privilegi vengono archiviate nelle tabelle dei privilegi (grant tables) della base di dati mysql, creata in fase di installazione del DBMS. Altri comandi utili per amministrare gli utenti sono:
- revoke: revoca i privilegi.
- drop user: per eliminare un utente.
- set password: per associare una parola chiave ad un utente.
- show grants: per mostrare i comandi grant eseguiti per un utente. Utile per duplicare i privilegi di un utente per un altro utente.
- show privileges: per mostrare tutti i privilegi che possono essere assegnati in generale.
E' giunta l'ora di creare il database univ secondo lo schema relazionale sopra descritto. Per far ciò possiamo usare il comando create database:
create database univ;
Occorre essere un utente con il privilegio create sul database creato. E' possibile specificare il character set (l'insieme di caratteri da usare) e il relativo collation (l'ordinamento dei caratteri nell'insieme scelto) come segue:
create database univ character set utf8 collate utf8_general_ci;
Alcuni comandi connessi alla creazione di un database sono:
- show databases: mostra la lista dei database presenti;
- drop database: rimuove un database e tutto il suo contenuto.
- show character set: mostra i character set disponibili;
- show collate: mostra i collate disponibili.
E' possibile selezionare il database corrente su cui lavorare con il comando use:
use univ;
Ora possiamo creare le tabelle usando la parte di definizione dei dati di SQL. Per creare una tabella si usa il comando create table. Ad esempio, i seguenti comandi creano le tre tabelle della base di dati univ e i relativi vincoli di integrità:
create table studente
(
matricola varchar(8) primary key,
nome varchar(20) not null,
cognome varchar(20) not null,
data date,
luogo varchar(30)
)
comment = 'Questa tabella contiene studenti universitari'
engine = InnoDB;
create table corso
(
nome varchar(30),
cdl varchar(30),
facolta varchar(30) not null,
docente varchar(30),
primary key (nome, cdl)
)
comment = 'Questa tabella contiene corsi universitari'
engine = InnoDB;
create table esame
(
studente varchar(8),
corso varchar(30),
cdl varchar(30)
data date not null,
voto tinyint not null,
lode enum('si','no') not null default 'no',
primary key (studente, corso, cdl),
foreign key (studente) references studente(matricola)
on update cascade on delete cascade,
foreign key (corso, cdl) references corso(nome, cdl)
on update cascade on delete cascade
)
comment = 'Questa tabella contiene esami sostenuti da studenti universitari'
engine = InnoDB;
Seguono alcune osservazioni:
- Le tabelle possono essere create con diversi tipi (detti anche engine). Il tipo della tabella viene specificato dal parametro engine del comando create, oppure in fase di avvio del server usando l'opzione --default-storage-engine=type, dove type va sostituito con il tipo che deve essere assegnato alla tabelle create durante la sessione. Tabelle di tipo diverso possono coesistere nella medesima base di dati. I principali engine offerti da MySQL sono:
- MyISAM: questo è il tipo di default. Non supporta le chiavi esterne e le transazioni e quindi, se tali caratteristiche non servono, è più efficiente e richiede meno spazio di memoria. Permette di effettuare ricerche fulltext e di definire indici fulltext per agevolare tali ricerche. Permette inoltre di creare indici di tipo btree;
- InnoDB: è ideale per ambienti multi-utente ad alte prestazioni. Gestisce l'integrità referenziale, le transazioni e il locking delle righe. Permette di creare indici del solo tipo btree;
- MEMORY: è un engine non-transazionale che usa solo la memoria centrale per salvare i dati delle tabelle. Quindi può essere usato per tabelle temporanee non persistenti (lo schema è comunque salvato in memoria secondaria). Permette di creare indici di tipo hash o btree.
- il formato di archiviazione delle righe viene specificato dal parametro row_format, aggiunto dopo la definizione delle colonne e dei vincoli della tabella, e può assumere i valori di dynamic (a lunghezza variabile), fixed (a lunghezza prefissata) e compressed (compresso).
- MySQL offre numerosi tipi di dato da associare agli attributi, tra cui boolean, bit[m] (sequenza di bit di lunghezza m), blob (oggetto binario di grosse dimensioni), text (testo di grosse dimensioni), enum (tipo enumerativo), set (tipo insieme). Ad esempio, abbiamo usato il tipo enum per l'attributo lode della tabella esame.
- il costrutto index permette di creare indici, anche su più colonne. Un indice può avere un nome e un tipo. Gli indici btree sono supportati da tutte le tabelle. Le tabelle di tipo MEMORY possono avere indici hash. Le tabelle MyISAM permettono inoltre indici fulltext (per indicizzare del testo) e spatial (per indicizzare dati geografici). Si noti che un indice viene creato automaticamente per gli attributi della chiave primaria, per quelli dei chiavi candidate (creati con il vincolo unique), e per quelli di chiavi esterne.
- MySQL non implementa il costrutto check (anche se presente nella sintassi), dunque non è possibile creare domini, vincoli generici e asserzioni come in SQL standard.
- E' possibile definire attributi codice specificando il flag auto_increment dopo il tipo dell'attributo. L'attributo codice deve avere un tipo intero.
- E' possibile specificare un commento per la singola colonna o per l'intera tabella mediante l'opzione comment.
E' possibile creare una tabella a partire dallo schema di un'altra tabella, possibilmente importando parte dei dati, come mostrato nei due esempi che seguono:
create table corsoInformatica like corso; create table corsoInformatica as select * from corso where cdl = "Informatica";
Nel primo caso, viene creata una tabella vuota corsoInfomatica con lo stesso schema di corso, nel secondo la tabella corsoInformatica viene creata e popolata con i corsi di Informatica.
Alcuni comandi connessi alla creazione delle tabelle seguono:
- alter table: cambia lo schema di una tabella;
- rename table: rinomina tabella;
- drop table: rimuove una tabella e il suo schema;
- show tables: mostra le tabelle presenti nel database corrente;
- show table status: mostra lo stato delle tabelle del database corrente;
- show columns: mostra informazione sulle colonne di una tabella. Il comando describe table è una scorciatoria per show columns from table;
- show index: mostra informazione sugli indici di una tabella;
- show engines: mostra gli engine disponibili e quello di default;
- show create table: mostra il comando usato per creare una tabella;
Ad esempio, possiamo aggiungere un indice sui campi nome e cognome della tabella studente con il comando alter:
alter table studente add index IndNome (nome(5), cognome(5));
L'indice definito si chiama IndNome e si basa sui primi 5 caratteri di entrambi gli attributi nome e cognome. Se non specifichiamo un nome, il sistema assegna all'indice un nome univoco, che può essere visto con il comando show create table.
Per vedere le caratteristiche dell'indice creato, in particolare il nome e il tipo, usare il comando show index come segue:
show index from studente;
Per rimuovere l'indice creato, possiamo usare il comando alter come segue:
alter table studente drop index IndNome;
Siamo pronti ad inserire i dati nelle tabelle. Usiamo il comando insert come segue:
insert into studente(matricola, nome, cognome, data, luogo)
values ('ALSBRT66', 'Alessio', 'Bertallot', '1966-12-12', 'Torino'),
('PSQMLF56', 'Pasquale', 'Molfetta', '1956-02-11', 'Bari'),
('NCLSVN70', 'Nicola', 'Savino', '1970-04-02', NULL);
insert into corso(nome, cdl, facolta, docente)
values ('Basi di Dati', 'TWM', 'Scienze', 'Franceschet'),
('Basi di Dati', 'Informatica', 'Scienze', 'Montanari'),
('Tecnologie XML', 'TWM', 'Scienze', 'Franceschet');
insert into esame set
studente = 'ALSBRT66',
corso = 'Basi di Dati',
cdl = 'TWM',
data = '2007-10-30',
voto = '30';
insert into esame set
studente = 'ALSBRT66',
corso = 'Tecnologie XML',
cdl = 'TWM',
data = '2007-09-30',
voto = '30',
lode = 'si';
insert into esame set
studente = 'PSQMLF56',
corso = 'Tecnologie XML',
cdl = 'TWM',
data = '2007-09-18',
voto = '30';
Si noti che la seconda sintassi (usata per la tabella esame) permette di inserire solo i valori per gli attributi che ci interessano. Gli attributi non specificati assumono il valore di default, se è stato specificato, oppure null altrimenti.
Vediamo le operazioni di aggiornamento dei dati. Supponiamo di aver sbagliato il voto dell'ultimo inserimento nella tabella esame. Possiamo aggiornare la corrispondente riga con il comando update:
update esame
set voto = '18'
where studente = 'PSQMLF56' and
corso = 'Tecnologie XML' and
cdl = 'TWM';
Per fare uno scherzo ad Alessio Bertallot, potremmo cancellare tutti i sui esami con il seguente comando delete:
delete from esame
where studente in (select matricola
from studente
where nome = 'Alessio' and cognome = 'Bertallot');
Supponiamo di aver salvato i dati cancellati in un documento di testo data.txt contenuto nella cartella sql del database univ avente il seguente contenuto:
ALSBRT66|Basi di Dati|TWM|2007-10-30|30|no ALSBRT66|Tecnologie XML|TWM|2007-09-30|30|si
Possiamo reinserire i dati nella tabella esame a partire da tale documento con il comando load data infile:
load data infile 'univ/sql/data.txt' into table esame fields terminated by '|' lines terminated by '\n';
Il carattere \n è il separatore di linea di default in Unix, mentre in Windows le linee sono terminate da \n\r.
Proviamo a violare i vincoli di integrità relazionali. Violiamo un vincolo di dominio:
update esame
set voto = 'A'
where studente = 'PSQMLF56' and
corso = 'Tecnologie XML' and
cdl = 'TWM';
Si noti che l'inserimento viene comunque effettuato usando un valore di default predefinito (0 per gli interi) ma viene segnalato un avvertimento (warning) che avvisa del valore scorretto per la colonna voto. Per vedere gli avvertimenti provocati dall'ultimo comando eseguito usare il comando show warnings.
Violiamo un vincolo di obbligatorietà per un attributo:
update corso set facolta = NULL where nome = 'Tecnologie XML' and cdl = 'TWM';
Anche in questo caso l'inserimento viene comunque effettuato usando un valore di default predefinito ('', la stringa vuota, per le stringhe) ma viene segnalato un avvertimento che avvisa del valore non ammesso per la colonna facolta.
Violiamo ora un vincolo di chiave primaria inserendo uno studente duplicato:
insert into studente(matricola, nome, cognome, data, luogo)
values ('ALSBRT66', 'Andrea', 'Collavino', '1986-12-14', 'Udine');
In questo caso l'inserimento viene rifiutato e viene segnalata la violazioni di chiave primaria. Per vedere gli errori dell'ultimo comando eseguito usare show errors.
Violiamo quindi un vincolo di chiave esterna inserendo un esame per uno studente che non esiste:
insert into esame(studente, corso, cdl, data, voto, lode)
values ('MSMFRN72', 'Basi di Dati', 'TWM', '2007-10-30', '30', 'no');
Viene segnalato un errore di violazione di integrità referenziale e l'inserimento non viene effettuato. Similmente in caso di modifica.
E' possibile disattivare i controlli referenziali con il comando:
SET FOREIGN_KEY_CHECKS = 0;
e riattivarli con il comando:
SET FOREIGN_KEY_CHECKS = 1;
Verifichiamo ora le politiche referenziali. Modifichiamo la matricola di uno studente:
update studente set matricola = 'ALSBRT00' where matricola = 'ALSBRT66';
Le modifiche sono riportate a cascata nella tabella esame per le righe della matricola modificata in quanto abbiamo specificato la politica on update cascade per il vincolo referenziale esame(studente) --> studente(matricola).
Ristabiliamo la situazione precedente con una nuova modifica:
update studente set matricola = 'ALSBRT66' where matricola = 'ALSBRT00';
Cancelliamo ora uno studente:
delete from studente where matricola = 'ALSBRT66';
La cancellazione ha effetto a cascata nella tabella esame, dove vengono cancellate le tuple che si riferiscono allo studente rimosso. Questo perchè abbiamo specificato la politica on delete cascade per il vincolo referenziale esame(studente) --> studente(matricola).
Ristabiliamo la situazione precedente inserendo le tuple cancellate:
insert into studente(matricola, nome, cognome, data, luogo)
values ('ALSBRT66', 'Alessio', 'Bertallot', '1966-12-12', 'Torino');
insert into esame(studente, corso, cdl, data, voto, lode)
values ('ALSBRT66', 'Basi di Dati', 'TWM', '2007-10-30', '30', 'no'),
('ALSBRT66', 'Tecnologie XML', 'TWM', '2007-09-30', '30', 'si');
Ora possiamo interrogare la base di dati creata e popolata con il comando select. Vediamone alcuni esempi:
-- where
select nome, cognome
from studente
where data < '1979-12-31' and data > '1970-01-01';
-- order by
select nome, cognome, data
from studente
order by data desc;
-- join
select studente.nome, studente.cognome, esame.corso, esame.voto
from studente join esame on (studente.matricola = esame.studente);
-- left join
select studente.nome, studente.cognome, esame.corso, esame.voto
from studente left join esame on (studente.matricola = esame.studente);
-- right join
select studente.nome, studente.cognome, esame.corso, esame.voto
from studente right join esame on (studente.matricola = esame.studente);
-- join di più tabelle
select studente.nome, studente.cognome, corso.nome, corso.cdl,
corso.docente, esame.voto
from (studente join esame on (studente.matricola = esame.studente)) join
corso on (esame.corso = corso.nome and esame.cdl = corso.cdl);
Si noti che MySQL non supporta il full join.
-- operatori aggregati select count(*) as esami, avg(voto) as media, max(voto) as top, min(voto) as bottom from studente join esame on (studente.matricola = esame.studente) where studente.nome = 'Alessio' and studente.cognome = 'Bertallot'; -- group by select cdl, count(*) from corso group by cdl having count(*) > 0 order by count(*) desc; -- operatori insiemistici select studente.nome, studente.cognome, esame.corso, esame.voto from studente left join esame on (studente.matricola = esame.studente) union select studente.nome, studente.cognome, esame.corso, esame.voto from studente right join esame on (studente.matricola = esame.studente);
L'ultima query implementa il full join usando l'operatore union. Gli operatori intersect e except non sono supportati, ma possono essere simulati con le interrogazioni annidate.
-- interrogazioni annidate
select nome, cognome
from studente
where matricola in (select studente from esame);
select nome, cognome
from studente
where matricola not in (select studente from esame);
select nome, cognome
from studente join esame on (studente.matricola = esame.studente)
where voto <= all (select voto from esame);
select nome, cognome
from studente join esame on (studente.matricola = esame.studente)
where voto = (select min(voto) from esame);
select S1.nome, S1.cognome
from studente S1
where exists (select *
from studente S2
where (S1.data = S2.data) and
(S1.matricola <> S2.matricola));
E' possibile ridirigere il risultato di una interrogazione in un file come segue:
-- output su file select * from esame into outfile 'univ/sql/data2.txt' fields terminated by '|' lines terminated by '\n';
Il comando load into file permette di caricare i dati letti da un file.
Vediamo ora la definizione di viste (comando create view) e il loro uso nelle interrogazioni:
create view algorithm = merge curriculum (nome, corso, docente, data, voto, lode) as
select concat(studente.nome, ' ', studente.cognome),
concat(corso.nome, ' (', corso.cdl, ')'),
corso.docente, esame.data, esame.voto, esame.lode
from (studente join esame on (studente.matricola = esame.studente)) join
corso on (esame.corso = corso.nome and esame.cdl = corso.cdl);
select nome, avg(voto) as media
from curriculum
where (docente = 'Franceschet')
group by nome
having avg(voto) >= 27
order by avg(voto) desc;
MySQL non supporta viste temporanee (clausola with) e neanche viste ricorsive; ogni vista è inserita stabilemente nello schema e può essere rimossa con il comando drop view. E' possibile specificare l'algoritmo con cui la vista viene gestita: le opzioni sono merge che riscrive una interrogazione che usa una vista usando la definizione della vista, e temptable che crea una tabella temporanea per la vista e usa tale tabella nella valutazione di interrogazioni che ne fanno uso.
Le viste fanno parte dello schema e sono visibili con il comando show create view.
Le regole attive (trigger) possono essere create col comando create trigger e rimosse col comando drop trigger. Nella versione usata di MySQL, le regole attive non vengono attivate dalle modifiche referenziali (le modifiche a cascata sulla tabella secondaria come conseguenza delle azioni fatte su una tabella principale).
Vediamo un paio di esempi. Vogliamo aggiungere un attributo calcolato media alla tabella studente che registra la media dei voti degli studenti. Creiamo il campo, lo aggiorniamo allo stato corrente e infine creiamo i trigger per gli eventi di modifica, cancellazione e inserimento di un nuovo esame:
-- regole attive
alter table studente
add column media tinyint;
update studente
set media = (select avg(voto)
from esame
where matricola = esame.studente);
create trigger updateAvg
after update on esame
for each row
update studente
set media = (select avg(voto)
from esame
where matricola = esame.studente)
where matricola = new.studente;
create trigger deleteAvg
after delete on esame
for each row
update studente
set media = (select avg(voto)
from esame
where matricola = esame.studente)
where matricola = old.studente;
create trigger insertAvg
after insert on esame
for each row
update studente
set media = (select avg(voto)
from esame
where matricola = esame.studente)
where matricola = new.studente;
Proviamo i trigger con i seguenti comandi di aggiornamento:
update esame
set voto = '18'
where (studente = 'ALSBRT66') and
(corso = 'Basi di Dati') and
(cdl = 'TWM');
delete from esame
where studente = 'ALSBRT66' and
corso = 'Basi di Dati' and
cdl = 'TWM';
insert into esame(studente, corso, cdl, data, voto, lode)
values ('ALSBRT66', 'Basi di Dati', 'TWM', '2007-10-30', '30', 'no'),
('PSQMLF56', 'Basi di Dati', 'TWM', '2007-10-30', '20', 'no'),
('NCLSVN70', 'Basi di Dati', 'TWM', '2007-10-30', '25', 'no');
Creiamo quindi un paio di trigger per fa sì che la lode ci sia solo quando il voto è uguale a 30. Si noti che questi trigger vengono chiamati prima dei rispettivi eventi:
delimiter // create trigger insertLode before insert on esame for each row begin if ((new.voto < 30) and (new.lode = 'si')) then set new.lode = 'no'; end if; end;// delimiter ; delimiter // create trigger updateLode before update on esame for each row begin if ((new.voto < 30) and (new.lode = 'si')) then set new.lode = 'no'; end if; end;// delimiter ;
Proviamo gli ultimi due trigger creati:
insert into esame(studente, corso, cdl, data, voto, lode)
values ('NCLSVN70', 'Tecnologie XML', 'TWM', '2007-10-30', '27', 'si');
update esame
set lode = 'si'
where (studente = 'NCLSVN70') and
(corso = 'Tecnologie XML') and
(cdl = 'TWM');
I trigger fanno parte dello schema e sono visibili con il comando show triggers.
MySQL supporta le transazioni su tabelle di tipo InnoDB. I relativi comandi sono:
- start transaction: inizia una transazione;
- commit: termina una transazione rendendone persistenti gli effetti;
- rollback: termina una transazione annullandone gli effetti;
- savepoint: stabilisce un punto salvo all'interno di una transazione;
- rollback to savepoint: annulla gli effetti della transazione fino al punto salvo nominato;
- set transaction: assegna il livello di isolamento delle future transazioni;
- lock: blocca l'accesso ad una tabella;
- unlock: sblocca l'accesso ad una tabella.
Seguono due esempi:
-- transazioni
start transaction;
insert into studente(matricola, nome, cognome, data, luogo)
values ('ELNDCC76', 'Elena', 'Di Cioccio', '1976-01-01', 'Monza');
insert into esame(studente, corso, cdl, data, voto, lode)
values ('ELNDCC76', 'Basi di Dati', 'TWM', '2007-11-02', '30', 'no');
commit;
start transaction;
insert into studente(matricola, nome, cognome, data, luogo)
values ('FBIVLO72', 'Fabio', 'Volo', '1972-04-18', 'Brescia');
insert into esame(studente, corso, cdl, data, voto, lode)
values ('FBIVLO72', 'Basi di Dati', 'TWM', '2007-11-02', '18', 'no');
rollback;
MySQL permetta la creazione di procedure e funzioni definite dall'utente (dette stored) in quanto vengono salvate assieme allo schema del database). I comandi create procedure e create function creano procedure e funzioni. Il loro corpo contiene comandi SQL e possibilmente altri costrutti tipici dei comuni linguaggi di programmazioni. La comunicazione con l'ambiente chiamante avviene attraverso parametri. Segue un esempio di procedura che calcola il numero di esami superati dallo studente la cui matricola viene passata come parametro:
delimiter // create procedure conta (in matricola varchar(8), out num INT) begin select count(*) into num from esame where studente = matricola; end; // delimiter ;
Si noti che abbiamo dovuto cambiare il delimitatore di comando in // in quanto il simbolo ; viene usato all'interno del corpo della procedura con un'altra semantica. Possiamo invocare una procedura o funzione con il comando call. Si noti che abbiamo anche usato in comando set per assegnare una variabile:
set @studente = 'ALSBRT66'; call conta(@studente, @num); select @studente, @num;
Le procedure fanno parte dello schema e sono visibili con i comandi show procedure code e show procedure status.
Infine, vediamo come salvare e ripristinare la nostra base di dati. Per fare il backup possiamo usare il programma mysqldump come segue:
mysqldump -u francesc -p --lock-tables --routines univ > /home/francesc/backup/backup.sql
L'effetto del comando è di esportare la base di dati univ in un file backup.sql. Tale file conterrà i comandi create e insert per ricreare la base di dati. L'opzione --lock-tables blocca le tabelle durante il backup, mentre --routines esporta anche le procedure e funzioni (i trigger e le viste vengono esportati di default). L'opzione --xml esporta il database in formato XML. Per ripristinare la base di dati è necessario ricrearla con il comando create database e eseguire il file backup.sql ad esempio con il comando source dal monitor di MySQL.
MySQL permette la connettività di applicazioni client sviluppate nel linguaggio Java attraverso un driver JDBC, chiamato MySQL Connector/J. MySQL Connector/J è un driver di tipo 4: questo significa che è scritto completamente in Java e che comunica direttamente con il server MySQL attraverso il protocollo MySQL. Si veda il tutorial della Sun dedicato a JDBC.