Networks of information consist of items of data linked together in some way. Perhaps the best known example is the World Wide Web.
The Web is a network in which the vertices are web pages and the edges are the hyperlinks that allow us to navigate from page to page. More precisely, there exists an edge from page P to page Q if page P contains at least one hyperlink pointing to page Q. Usually, the actual number of hyperlinks between two pages is not important and hence the network modelling the Web is an unweighted directed graph. Moreover, page self-links are ignored.
The Web was invented in 1989 by physicists Tim Berners-Lee at the European Organization for Nuclear Research (CERN). Berners-Lee proposed the HyperText Markup Language (HTML) to keep track of experimental data at CERN. An interesting excerpt of the original far-sighted proposal in which Berners-Lee attempts to persuade CERN management to adopt the new global hypertext system follows:
The Web structure was in fact envisioned much earlier. In 1945 Vannevar Bush wrote a today celebrated article in The Atlantic Monthly entitled "As We May Think" describing a futuristic device he called Memex. Bush writes:
The structure of the Web can be measured using a crawler, a computer program that automatically surfs the Web looking for pages using a breadth-first search technique. Web crawlers are typically exploited by Web search engines, such as Google, since knowing the structure of the Web is fundamental to provide to the users significant rankings of Web pages. More specifically, the modules involved in the Web search process are briefly described in the following:
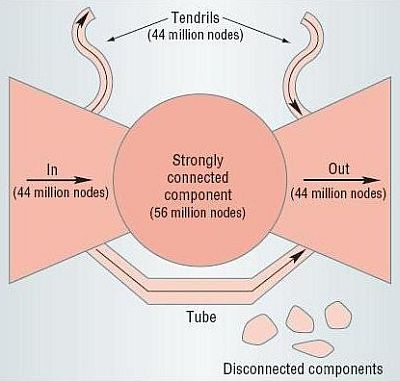
It turns out that the Web network has a bow-tie fragmented structure. This structure predicts the existence of four main continents of roughly the same size:
This structure significantly limits the Web's navigability, that is, how far we can get taking off from a given node. Starting from any page, we can reach only about one quarter of all documents. The rest are invisible to us, unreachable by surfing. Since the Web is explored by robots which navigate from page to page following the page hyperlinks, this heavily influences our knowledge of the Web.
Most academic papers refer to other previous papers, usually in a bibliography at the end of the paper. Academic citation networks are networks in which the nodes are bibliometric units, such as papers and journals, and the directed edges are the bibliographic citations between them.
Two typical examples are article citation networks, in which the vertices are papers and the edges are the bibliographic citations between papers, and journal citation networks, in which the nodes are academic journals and the edges are the bibliographic citations between papers published in the journals. In article citation networks, the actual number of citations between two papers is ignored and the network is represented as an unweighted directed graph. Furthermore, since paper citations point backward in time, from newer to older papers, article citation networks are acyclic graphs. On the other hand, journals citation networks are weighted directed graphs, where the edges are weighted with the actual number of citations between the involved journals. Since journals contain papers published in different periods, journal citation networks typically contain loops.
In general, if one paper cites another it is usually an indication that the contents of the earlier paper are relevant in some way to those of the later one, and hence citation networks are networks of relatedness of subject matter. Furthermore, citations are often a way of showing intellectual debt because the ideas and the results of the earlier paper have been useful for the investigations provided in the older paper. Hence, the number of citations received by one paper from other papers gives an indication of the impact of a paper within the academic community. The impact of the papers written by a scholar can be used as one criterion for the assessment of the quality of the research made by the scholar.
Recently, bibliometric indicators, like the Eigenfactor, have been proposed which exploit the topology of the journal citation network in order to compute importance scores for journals. The Eigenfactor indicator works similarly to the PageRank for Web pages, giving more importance to journals that are cited by other important journals. Hence, academic journals within a given field can be ranked by their importance, and these rankings can be exploited by, for instance, librarians in order to purchase the most important journals within a limited budged.
The databases of the Institute for Scientific Information (ISI) have been the most generally used data sources for citation data. The ISI was founded by Eugene Garfield in 1960 and acquired by Thomson (today Thomson-Reuters) in 1992. It provides access to many resources, in particular:
A major alternative to Web of Science is Elsevier's Scopus. Scopus, as Web of Science, contains mainly journal bibliometric information. The coverage of Web of Science and Scopus is largely similar. Both Web of Science and Scopus are subscription-based proprietary databases that are hand-maintained by professional staff. On the other hand, Google Scholar uses automated citation indexing and provides free access to more types of works, including journal articles, conference papers, books, theses, and reports.
Citation networks described so far are not the only possible network representation of citation patterns. An alternative representation is the cocitation network. Two papers are said to be cocited if they are both cited by the same third paper. Cocitation is often taken as an indicator that papers deal with related topics. A cocitation network is a network in which the vertices represent papers and the edges represent cocitation of pairs of papers. Notice that cocitation is a symmetric relationship, hence the edges in cocitation networks are undirected. It is also possible to provide a strength for the cocitation between two papers as the number of other papers that cite both and hence create a weighted cocitation network.
Another related concept is bibliographic coupling. Two papers are said to be bibliographically coupled if they cite the same other paper. Bibliographic coupling, like cocitation, can be taken as an indicator that the papers deal with related material. One can define a bibliographic coupling network, either weighted or not, in which the vertices are papers the undirected edges indicate bibliographic coupling.
Citation networks, in particular article citation networks, are in many ways similar to the World Wide Web. The vertices of the network hold information in the form of text and pictures, just as Web pages do, and the links from one paper to another play a role similar to the hyperlinks on Web pages, alerting the reader when information relevant to the topic of one paper can be found on another. Papers with many citation are often more influential than those with few, just as is the case with Web pages that are linked to by many other pages; in particular, the Eigenfactor bibliometric indicator has been designed to work in the journal citation network as the PageRank does on the Web network. Finally, it is typical for a scholar to surf the citation network by following chains of citations from paper to paper just as computer users surf the Web from page to page.
However, quantitative studies on citation networks are much older that the Web and go back to the 1960s with the studies of de Solla Price. Notably, Sergey Brin and Larry Page have been inspired by works on citation networks in the development of the PageRank algorithm for Google. Studies on academic publications and citations fall within the field of bibliometrics, a branch of information and library science.
There are other types of citations besides article citations networks. These includes citations in patents and in legal opinions. Patents are temporary grants of ownership for inventions, which give their holder the right to take legal action against others who attempt to profit without permission from the protected invention. They are typically issued to inventors by national governments after a review process to determine whether the invention in question is original and has not previously been invented by someone else.
In applying for a patent, an inventor must describe the invention is sufficient detail. In particular, the inventor must detail the relationships between the invention and previously patented inventions and in doing so the inventor will usually cite previous patents. Citations in patents may highlight dependencies between technologies, but more often patent citations are defensive, meaning that the inventor cites the patent for a previous technology and then presents an argument for why the new technology is sufficiently different from the old one. Typically there are a number of rounds of communication, back and forth between the government patent examiner and the inventor, before a patent application is finally accepted or rejected. During this process extra citations are often added either by the inventor or by the examiner.
If a patent is granted, it is published, citations and all, so that the public may know which technologies have patent protection. For example, here is the patent with citations of the PageRank algorithm used by Google. These published patents provide a source of citation data that can be used to construct networks similar to the networks for citations between papers: the vertices are patents, each identified by a unique patent number, and the directed edges are citations between patents. Like article citation networks, patent networks are mostly acyclic, with edges running from more recent patents of older ones. The structure of patent networks reflects the organization of human technology in much the same way that academic citations reflect the structure of research knowledge.
Another class of citation network is that of legal citation networks. A legal opinion is a narrative essay written by a judge explaining his or her reasoning and conclusions that accompanies the ruling in a case. If a court decides that an opinion should be published, the opinion is included in a volume from a series of books called law reports. Published opinions of courts are also collectively referred to as case law, which is one of the major sources of law in common law legal systems adopted in anglo-saxon countries. On the other hand, in civil law legal systems, which are inspired by Roman law, laws are codified, and not (as in common law) determined by judges.
It is common practice in writing a legal opinion to cite previous opinions issued in other cases in order to establish precedent or occasionally to argue against it. Thus, like academic papers and patents, legal opinions form a citation network, with opinions being the vertices and citations being the directed edges. Again the network is approximately acyclic. The legal profession has long maintained indexes of citations between opinions for use by lawyers, judges, and scholars. In the US, two commercial services, LexisNexis and Westlaw, provide data on legal opinions. In principle, it would be possible to construct networks of cocitation or bibliographic coupling between either patents or legal opinions. Furthermore, Google scholar provides freely the possibility to retrieve citations between patents and between US legal opinions as well.
A peer-to-peer (P2P) file-sharing network is a network in which the nodes are computers containing information in the form, usually, of discrete files, and the edges between them are virtual links established for the purpose of sharing the contents of those files. The links exist only in software - they indicate only the intention of one computer to communicate with another should the need arise.
P2P networks are typically used as a vehicle for distributed databases, particularly for storage and distribution of music and movies, often illegally. Legal uses include local sharing of files on corporate networks and the distribution of open-source software. As an example, the network of router-to-router communications for routing packets on the Internet.
The point of a P2P network is that data is transferred directly between computers belonging to two end users, two peers, of the network. This model contrasts with the client-server model, in which central server computers supply requested data to a large number of client machines. The P2P model is favored for illicit sharing of copyrighted material because the owner of a centralized server can easily be obliged to turn off the server by legal action, but such action is more difficult when no central server exists.
On P2P networks each computer is home to some information, but no computer has all the information. If the user of a computer requires information stored on another computer, that information can be transmitted over the Internet - standard Internet protocols are perfectly adequate to support this model. Things get interesting, however, when one wants to search for the desired information on the P2P network. One way to do this is to have a central server containing none of the information but just an index of which information is on which computers. Such a system was employed by the early file-sharing network Napster, but the central index is, once again, susceptible to legal action, and such challenges were in the end responsible for shutting Napster down.
To avoid this problem, developers have turned to distributed schemes for searching. An illustrative example of a P2P system with distributed search is Gnutella. In the simplest incarnation of this system, when a user instructs his or her computer to search the network for a specific file the computer sends out a message to its network neighbors asking whether they have the file. If they do, they arrange to transmit it back, otherwise they pass the message on to their neighbors, and so forth in a breath-first search of the network. This strategy works, but only on small networks. Since it requires messages to be passed between many computers for each individual search, the volume of network traffic eventually swamp the available data bandwidth.
To get around this problem, most modern P2P networks make use of supernodes, high-bandwidth peers connected to one another to form a supernode network over which searches can be performed quickly. A supernode acts like a local exchange in a telephone network. Each normal node, or client, attaches to a supernode. The clients of the supernode communicates to it a list of files they possess. An individual client wanting to perform a search then sends its search query to the local supernode, which conducts a breadth-first search over the supernode network to find the requested file. Since each supernode records all items that its clients have, the search on the entire P2P network can be performed by performing a search on the fast network of supernodes and no client resources are used.
A type of information network important for technology and commerce is the recommender network. Recommender networks represent people's preferences for things, such as for products sold by a retailer. Online merchants, for instance, keep records of which customers bought which products and sometimes ask them whether they liked the products. As another example, many large supermarkets chains record the purchases made by each of their regular customers, usually identified by a barcode card that is scanned when purchases are made.
The appropriate representation of a recommender network is as a bipartite graph in which the two types of vertices represent products and customers, with edges connecting customers to the products they buy or like. One can add also weights to the edges to indicate how often the person bought the product of how the person likes it.
The primary commercial interest in recommender networks arises from their use in collaborative filtering system, also called recommender systems. These are computer algorithms that try to guess items that people will like by comparing a person's known preferences with those of other people that bought similar products. If person A bought or likes many of the same products as persons B, C, and D, and if persons B, C, and D all bought or like some further item that A has never bought or expressed an opinion about, then maybe A would like that item too. The website Amazon.com, for instance, uses collaborative filtering to recommend book titles, and many supermarkets print out discount coupons to customers for products that the customer has never bought but might be interested to try.
Another type of information network, also bipartite in form, is the keyword index. Consider a set of documents containing information on various topics. For instance, a set of academic papers or a set of Web pages. One can construct an index to that set such that, for each keyword, a list of documents containing the keyword is recorded. Such indexes can be represented as a bipartite graph in which the two vertex types are keywords and documents, and the edges represent the occurrence of keywords in documents.
Such indexes are used for instance by Web search engines to retrieve the relevant Web pages after the user has entered some keywords using the Web engine interface. They are also used as a basis for techniques to find similar documents. If one has a keyword index to a set of documents and finds that two documents share a lot of keywords, it may be an indication that the two cover similar topics. The problem of finding documents with similar keywords is in many ways similar to the problem of finding buyers who like similar products, hence algorithms for recommender systems can be used in this context.
The identification of similar documents can be useful when searching through a body of knowledge. Search engines that can tell when documents are similar may be able to respond more usefully to user queries because they can return documents that do not in fact contain the keywords searched, but which are similar to documents that do. In case where a single concept is called by more than one name this may be very effective. In the context of information retrieval, this semantic search technique is referred to as latent semantic indexing, which is based on the application of the matrix technique known as singular value decomposition to the bipartite network of documents and keywords.