Codifica di Huffman
Nel 1952 David Huffman sviluppò una codifica binaria a lunghezza variabile dei caratteri che può essere applicata per comprimere documenti. L'idea alla base della codifica è di rappresentare i caratteri più frequenti in un testo con un minore numero di bit. Ciò può risultare vantaggioso, in particolare, per documenti scritti in un linguaggio naturale, poiché la frequenza delle diverse lettere dell'alfabeto è tuttaltro che uniforme.
Per determinare una simile codifica viene costruito un albero binario le cui foglie sono associate ai caratteri dell'alfabeto e si trovano a livelli più profondi (più lontane dalla radice) se i corrispondenti caratteri risultano meno frequenti. Il codice binario di un carattere si determina seguendo il percorso che collega la radice alla foglia associata: gli spostamenti a sinistra (scendendo di un livello) vengono rappresentati da 0 e quelli a destra da 1. (I nodi dell'albero binario o sono foglie o hanno due nodi figli, identificati come sinistro e destro.)
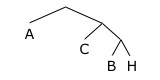
Considerando l'albero illustrato in figura, basato sulle tipiche frequenze relative di quattro lettere dell'alfabeto italiano, A verrebbe codificata con un solo bit 0, B con 110, C con 10 e H con 111. Quindi 110010111 sarebbe la codifica di BACH, 110010100 quella di BACCA (in questi esempi i testi sono troppo brevi per apprezzare i vantaggi della codifica di Huffman).